
In an earlier blog post I explained the motivation for a series of “Rosetta Stone” posts which described the ecosystem for different programming languages. This post covers Rust, the associated GitHub repository with some minimal code is here. This blog post aims to provide some discussion around technology choices whilst the GitHub repository provides details of what commands to execute and a minimal example project.
I became interested in Rust because a number of new tools such as uv and ruff for the Python ecosystem are written in Rust. It’s fair to say there has been a buzz around the language in programming circles for some years.
About Rust
Rust started out as a personal project by Graydon Hoare, an employee of Mozilla, in 2006. It was adopted by Mozilla in 2009 and in 2012 the first public release was made. It was originally designed with a focus on memory management and memory safety. It stands with C and assembly as the only languages supported in the development of the Linux kernel. I read the The Rust Programming Language book recently, the distinguishing feature of Rust is the borrow checker and ownership model which is what gives it strong memory safety credentials.
Rust is named for the rust fungi, not the corrosion of iron but it seems few people realise this!
Rust currently ranks 13th on the TIOBE index but has been regularly voted the most admired language on the Stackoverflow rankings.
How is the language defined?
The home for the Rust language is here. Rust evolves through an RFC (request for comments) process, which can be found in the Rust RFC Book. Currently there is no formal specification for the language but there is an exercise to write one.
New versions of the language are released every 6 week (see here). Breaking changes can be introduced in editions (once every 3 years with the next edition, 2024, due in February 2025) but upgrading between editions is optional and there are tools to support version migrations. For more about the edition process see here.
There is a roadmap for the 2024 edition (see here) and presumably once that is released the next roadmap will be developed.
Rust Compilers
The Rust compiler is rustc, there are some alternatives but they are experiments rather than production systems. Typically rustc is invoked with the cargo package manager, see below. My first impression was that the compiler provided really good error messages.
Details of installation can be found here in the accompanying GitHub repository. Installing the whole Rust toolchain is ridiculously simple.
Package management
cargo is the Rust package manager, it is also typically used to compile code to produce a “crate” which may be a binary or library.
Rather neatly invoking cargo to produce a new package also creates a new Git repository with the appropriate layout:
cargo new hello_world --bin
This generates a cargo.toml file which defines the project and dependencies, and on compile a cargo.lock file is produced which specifies exactly the versions of all the dependences. This parallels the NPM system for JavaScript/TypeScript. There is also a --lib flag which generates a layout for a library package. In practice this is just a starting point, your code may include both binaries and libraries for which you will need to edit the cargo.toml file. However, this cargo new process reflects how I would start a project in Python.
The standard library is here, there are no built-in CSV or JSON libraries – regular readers will recall I use this as a measure of a language’s completeness since my favoured language, Python, has them! Others may have different opinions.
Third party Rust crates can be found on the crate registry.
Virtual environments
Rust does not require virtual environments since cargo fetches the appropriate packages on compile, it uses a local cache of packages but this is a true cache – if the version of a package is not in the cache then it is fetched.
Project layout for package publication
cargo new generates a minimal project layout. More generally the conventional project layout is shown below (see here) when code is compiled a target directory is created for the compiled code.
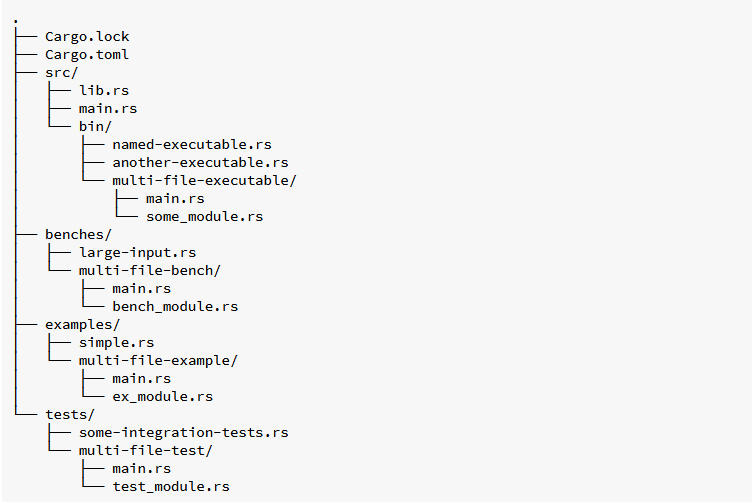
It is rather nice having a mandated project layout!
Testing
A testing framework is built-in and a skeleton test is included when a --lib project is created by cargo The tests look like this:

This is essentially a unit test and the intention in Rust is that the unit tests sit next to the functions which they test, in Python unit tests tend to be separated into tests directory. In a Rust project the tests directory holds integration tests. There is a third type of test, doctests which are embedded in the comments intended for documentation.
All three types of test can be run with cargo test.
The built-in test functionality does not include features such as mocks or parameterized tests but there are third party crates to provide this functionality.
Static analysis and formatting tools
Clippy is the built-in linter, used in addition to rustfmt, the formatter. The are invoked using cargo with cargo fmt and cargo clippy. As a compiled language the compiler provides static analysis too. I would not expect alternatives to clippy or rustfmt to gain much traction since these appear to be the “official” tools.
Documentation Generation
rustdoc is the standard documentation generator tool (see here), working from comments in code and invoked using cargo doc. It feels to me that there is scope for alternatives to rustdoc although perhaps I am mixing up the documentation generation engine with the standards for code comments for documentation which have arisen in Python.
Wrapping up
I was struck by how everything is pretty much built-in for Rust; compiling, packaging, testing, formatting, and linting. All of these tools can be driven from the package management tool, cargo. It is almost like the design team was trying to make the job of writing this post as easy as possible! In writing Rust code in associated with this post I found the built-in test framework missing features (like mocks and parameterization which I’m used to in Python), similarly the documentation system is quite simple so perhaps in time alternatives will start to predominate.
My “home” language of Python has acquired these features over a long period of time, utilizing third party libraries and tools that eventually became de facto standards.
It would be nice to make a comparison with Go which occupies a similar space in programming as a relatively recent arrival with what I believe is a similarly full tool suite.
I welcome comments, probably best on Mastodon where you can find me here.


