
This blog post is designed to clarify my thinking around installing Python packages and the use of setup.py, setup.cfg and pyproject.toml files. Hopefully it will be a useful reference for other people, and future me.
It is stimulated by my starting work on a new project where we have been discussing best practices in Python programming, and how to layout a git repository containing Python code. More broadly it is relevant to me as someone who programmes a lot in Python, mainly for my own local use, but increasingly for other people to consume my code. Prior to writing this the layout of my Python repositories was by a system of random inheritance dating back a number of years.
The subject of Python packaging, installation and publication is a bit complicated for mainly historic reasons – the original distutils module was created over 20 years ago. A suite of tools have grown up either as part of the standard library or de facto standards, and have evolved over time. Some elements are contentious in the sense that projects will have lengthy arguments over whether or not to support a particular method of configuration. A further complication for people whose main business is not distributing their code is that it isn’t necessarily at the start of a project and may never be relevant.
Update: I have updated this blog post 5th May 2023, the change is that project settings formerly in setup.cfg can now go in pyproject.toml, as per PEP-621 – described in more detail in the PyPA documentation. Currently I only use setup.cfg for flake8 configuration. A reader from Mastodon commented that setup.py is not required for installation of a package but is required for build/publication.
tl;dr
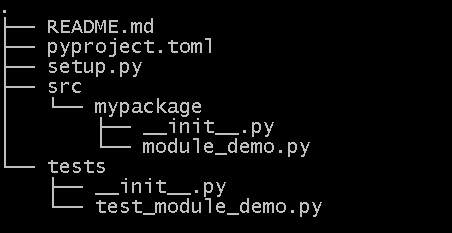
Structure your Python project like this with setup.py and pyproject.toml in the top level with a tests directory and a src directory with a package subdirectory inside that:
The minimal setup.py file simply contains an invocation of the setuptools setup function, if you do not intend to publish your project then no setup.py file is required at all, pip install -e . will work without it:

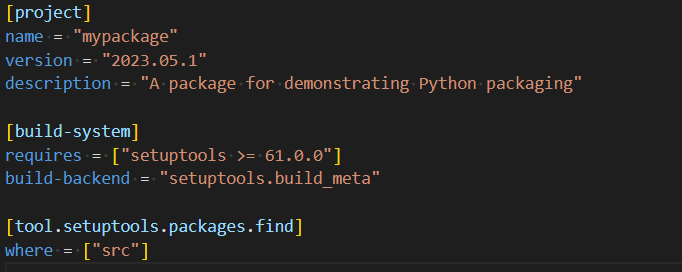
Setup.cfg is no longer required for configuring a package but third-party tools may still use it. Put at least this in pyproject.toml:
Then install the project locally:
pip install -e .
If you don’t do this “editable installation” then your tests won’t run because the package will not be installed. An editable install means that changes in the code will be immediately reflected in the functionality of the package.
It is common and recommended practice to use virtual environments for work in Python. I use the Anaconda distribution of Python in which we setup and activate a virtual environment using the following, to be run before the pip install statement
conda create -n tmp python=3.9
conda activate tmp
There is a copy of this code, including some Visual Code settings, and a .gitignore file in this GitHub repository: https://github.com/IanHopkinson/mypackage
Setup.py and setup.cfg
But why should we do it this way? It is worth stepping back a bit and defining a couple of terms:
module – a module is a file containing Python functions.
package – a package is a collection of modules intended to be installed and used together.
Basically this blog post is all about making sure import and from ... import ... works in a set of distinct use cases. Possibilities include:
- Coding to solve an immediate problem with no use outside of the current directory anticipated – in this case we don’t need to worry about
pyproject.toml,setup.cfg,setup.pyor even__init__.py. - Coding to solve an immediate problem with the potentially to spread code over several files and directories – we should now make sure we put an empty
__init__.pyin each directory containing module files. - Coding to provide a local library to reuse in other projects locally this will require us to run
python setup.py developor betterpip install -e . - Coding to provide a library which will be used on other systems you control again using
pip install -e . - Coding to provide a library which will be published publicly, here we will need to additionally make use of something like the packaging library.
I am primarily interested in cases 3 and 4, and my projects tend to be pure Python so I don’t need to worry about compiling code. More recently I have been publishing packages to a private PyPI repository but that is a subject for another blog post.
The setup.py and setup.cfg files are artefacts of the setuptools module which is designed to help with the packaging process. It is used by pip whose purpose is to install a package either locally or remotely. If we do not configure setup.py/setup.cfg correctly then pip will not work. In the past we would have written a setup.py file which contained a bunch of configuration information but now we should put that configuration information into setup.cfg which is effectively an ini format file (i.e. does not need to be executed to be read). This is why we now have the minimal setup.py file.
It is worth noting that setup.cfg is an ini format file, and pyproject.toml is a slightly more formal ini-like format.
What is pyproject.toml?
The pyproject.toml file was introduced in PEP-518 (2016) as a way of separating configuration of the build system from a specific, optional library (setuptools) and also enabling setuptools to install itself without already being installed. Subsequently PEP-621 (2020) introduces the idea that the pyproject.toml file be used for wider project configuration and PEP-660 (2021) proposes finally doing away with the need for setup.py for editable installation using pip.
Although it is a relatively new innovation, there are a number of projects that support the use of pyproject.toml for configuration including black, pylint and mypy. More are listed here:
https://github.com/carlosperate/awesome-pyproject
Where do tests go?
Tests go in a tests directory at the top-level of the project with an __init__.py file so they are discoverable by applications like pytest. The alternative of placing them inside the src/mypackage directory means they will get deployed into production which may not be desirable.
Why put your package code in a src/ subdirectory?
Using a src directory ensures that you must install a package to test it, so as your users would do. Also it prevents tools like pytest incidently importing it.
Conclusions
I found it a useful exercise researching this blog post, the initial setup of a Python project is something I rarely consider and have previously done by rote. Now I have a clear understanding of what I’m doing, and I also understand the layout of Python projects. One of my key realisations is that this is a moving target, what was standard practice a few years ago is no longer standard, and in a few years time things will have changed again.
