
For a long time I have worked as a data scientist, and before that a physical scientist – writing code to do data processing and analysis. I have done some work in software engineering teams but only in a relatively peripheral fashion – as a pair programmer to proper developers. As a result I have picked up some software engineering skills – in particular unit testing and source control. This year, for the first time, I have worked as a software engineer in a team. I thought it was worth recording the new skills and ways of working I have picked up in the process. It is worth pointing out that this was a very small team with only three developers working about 1.5 FTE.
This blog assumes some knowledge of Python and source control systems such as git.
Coding standards
At the start of the project I did some explicit work on Python project structure, which resulted in this blog post (my most read by a large margin). At this point we also discussed which Python version would be our standard, and which linters (syntax/code style enforcers) we would use (Black, flake and pylint) – previously I had not used any linters/syntax checkers other than those built-in to my preferred editors (Visual Studio Code). My Python project layout used to be a result of rote learning – working in a team forced me to clarify my thinking in this area.
Agile development
We followed an Agile development process, with work specified in JIRA tickets which were refined and executed in 2 week sprints. Team members were subjected to regular rants (from me) on the non-numerical “story points” which have the appearance of numbers BUT REALLY THEY ARE NOT! Also the metaphor of sprinting all the time is exhausting. That said I quite like the structure of working against tickets and moving them around the JIRA board. Agile development is the subject of endless books, I am not going to attempt to describe it in any detail here.
Source control and pull requests
To date my use of source control (mainly git these days) has been primitive; effectively I worked on a single branch to which I committed all of my code. I was fairly good at committing regularly, and my commit messages were reasonable useful. I used source control to delete code with confidence and as a record of what I was doing when.
This project was different – as is common we operated on the basis of developing new features on branches which were merged to the main branch by a process of “pull requests” (GitHub language) / “merge requests” (GitLab language). For code to be merged it needed to pass automated tests (described below) and review by another developer.
I now realise we were using the GitHub Flow strategy (a description of source control branching strategies is here) which is relatively simple, and fits our requirements. It would probably have been useful to talk more explicitly about our strategy here since I had had no previous experience in this way of working.
I struggled a bit with the code review element, my early pull requests were massive and took ages for the team to review (partly because they were massive, and partly because the team was small and had limited time for the project). At one point I Googled for dealing with slow code review and read articles starting “If it takes more than a few hours for code to be reviewed….” – mine were taking a couple of weeks! My colleagues had a very hard line on comments in code (they absolutely did not want any comments in code!)
On the plus side I learnt a lot from having my code reviewed – often in pushing me to do stuff I knew I should have done. I also learned from reviewing other’s code, often I would review someone else’s code and then go change my own code.
Automated pipelines
As part of our development process we used Azure Pipelines to run tests on pull requests. Azure is our corporate preference – very similar pipeline systems can be found in GitHub and GitLab. This was all new to me in practical, if not theoretical, terms.
Technically configuring the pipeline involved a couple of components. The first is optional, we used Linux “make” targets to specify actions such as running installation, linters, unit tests and integration tests. Make targets are specified in a Makefile, and are involved with simple commands like “make install”. I had a simple MakeFile which looked something like this:
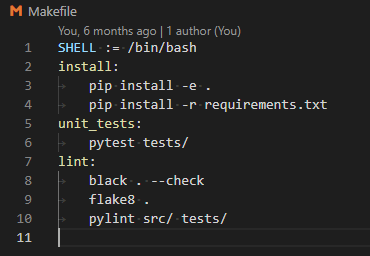
The make targets can be run locally as well as in the pipeline. In practice we could fix all issues raised by black and flake8 linters but pylint produced a huge list of issues which we considered then ignored (so we forced a pass for pylint in the pipeline).
The Azure Pipeline was defined using a YAML file, this is a simple example:
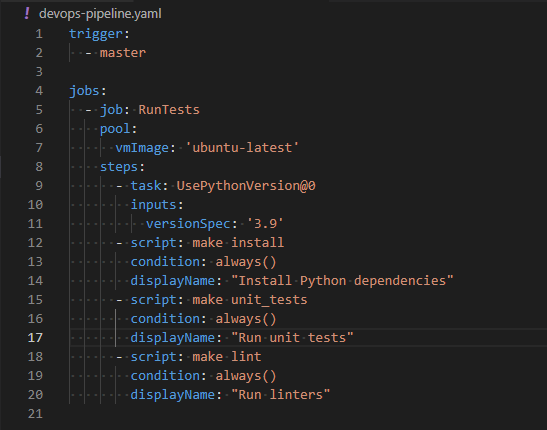
This YAML specifies that the pipeline will be triggered on attempting a pull request against a main branch. The pipeline is run on an Ubuntu image (the latest one) with Python 3.9 installed. Three actions are done, first installation of the Python package specified in the git repo, then unit tests are run and finally a set of linters is run. Each of these actions is run regardless of the status of previous actions. Azure Pipelines offers a lot of pre-built tasks but they are not portable to other providers, hence the use of make targets.
The pipeline is configured by navigating to the Azure Pipeline interface and pointing at the GitHub repo (and specifically this YAML file). The pipeline is triggered when a new commit is pushed to the branch on GitHub. The results of these actions are shown in a pretty interface with extensive logging.
The only downside of using a pipeline from my point of view was that my standard local operating environment is Windows with the git-bash prompt providing a Linux-like commandline interface. The pipeline was run on an Ubuntu image, which meant that certain tests would pass locally, but not in the pipeline, and were consequently quite difficult to debug. Regular issues were around checking file sizes (line endings mean that file sizes on Linux and Windows differ) and file paths – even with Python’s pathlib – are different between Windows and Linux systems. Using a pipeline forces you to ensure your installation process is solid, since the pipeline image is built on every run.
We also have a separate pipeline to publish the Python package to a private PyPi repository but that is the subject of another blog post.
Conclusions
I learnt a lot working with other, more experienced, software engineers and as a measure of the usefulness of this experience I have retro-fitted the standard project structure and make targets to my legacy projects. I have started using pipelines for other applications.
