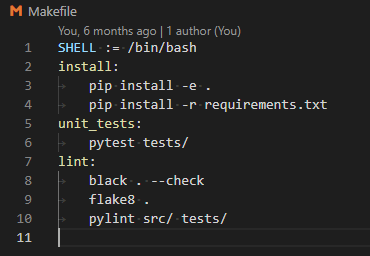
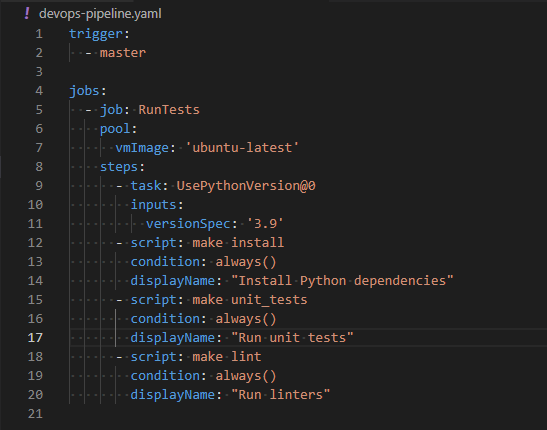
I have recently been thinking about versioning in Python, both of Python and also of the Python packages. This is a record of how it is done for a current project and the reasoning behind it.
Python Versioning
At the beginning of the project we made a conscious decision to use Python 3.9, however our package is also used by our Airflow code which does integration tests, and provides reference Docker images based on Python 3.7 (their strategy is to use the oldest version of Python still in support). This approach is documented here. And the end of life dates for recent Python versions are listed here:
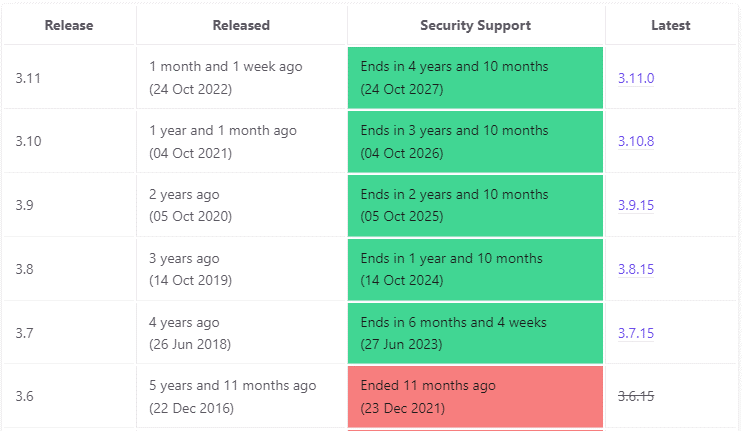
Since we started the project, Python 3.11 has been released so it makes sense to extend our testing from just Python 3.9 to include Python 3.7 and 3.11 too.
The project uses an Azure Pipeline to run continuous integration / continuous development tests, it is easy to add tests for multiple versions of Python using the following stanza in the configuration file for the pipeline.
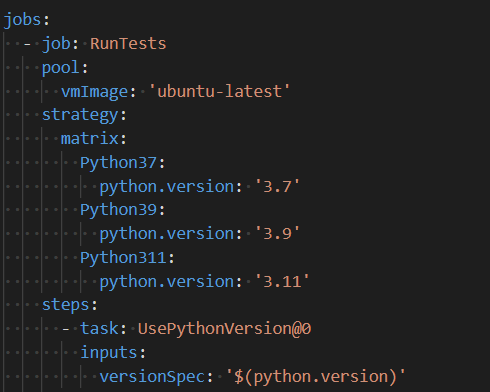
Extending testing resulted in only a small number of minor issues, typically around Python version support for dependencies which were easily addressed by allowing more flexible versions in Python’s requirements.txt rather than pinning to a specific version. We needed to address one failing test where it appears Python 3.11 handles escaping of characters in Windows-like path strings differently from Python 3.9.
Package Versioning
Our project publishes a package to a private PyPi repository. This process fails if we attempt to publish the same version of the package twice, where the version is that specified in the “pyproject.toml”* configuration file rather than the state of the code.
Python has views on package version numbering which are described in PEP-440, this describes permitted formats. It is flexible enough to allow both Calendar Versioning (CalVer – https://calver.org/) or Semantic Versioning (SemVer – https://semver.org/) but does not prescribe how the versioning process should be managed or which of these schemes should be used.
I settled on Calendar Versioning with the format YYYY.MM.Micro. This is a considered personal taste. I like to know at a glance how old a package is, and I worry about spending time working out whether I need to bump major, minor or patch parts of a semantic version number whilst with Calendar Versioning I just need to look at the date! I use .Micro rather than .DD (meaning Day) because the day to be used is ambiguous in my mind i.e. is the day when we open a pull request to make a release or when it is merged?
It is possible to automate the versioning numbering process using a package such as bumpversion but this is complicated when working in a CI/CD environment since it requires the pipeline to make a git commit to update the version.
My approach is to use a pull request template to prompt me to update the version in pyproject.toml since this where I have stored version information to date, as noted below I moved project metadata from setup.cfg to pyproject.toml as recommended by PEP-621 during the writing of this blog post. The package version can be obtained programmatically using the importlib.metadata.version method introduced in Python 3.8. In the past projects defined __version__ programmatically but this is optional and is likely to fall out of favour since the version defined in setup.cfg/pyproject.toml is compulsory.
Should you wish to use Semantic Versioning then there are libraries that can help with this, as long as you following commit format conventions such as those promoted by the Angular project.
Once again I am struck on how this type of activity is a moving target – PEP-621 was only adopted in November 2020.
* Actually when this blog post was started version information and other project metadata were stored in setup.cfg but PEP-621 recommends it is put in pyproject.toml and is preferred by the packaging library. Setuptools has parallel instructions for using pyproject.toml or setup.cfg, although some elements to do with package and data discovery are in beta.