
Dr Administrator
Author's posts
Apr 23 2013
Book review: JavaScript: The Good Parts by Douglas Crockford

This post was first published at ScraperWiki.
This week I’ve been programming in JavaScript, something of a novelty for me. Jealous of the Dear Leader’s automatically summarize tool I wanted to make something myself, hopefully a future post will describe my timeline visualising tool. Further motivations are that web scraping requires some knowledge of JavaScript since it is a key browser technology and, in its prototypical state, the ScraperWiki platform sometimes requires you to launch a console and type in JavaScript to do stuff.
I have two books on JavaScript, the one I review here is JavaScript: The Good Parts by Douglas Crockford – a slim volume which tersely describes what the author feels the best bits of JavaScript, incidently highlighting the bad bits. The second book is the JavaScript Bible by Danny Goodman, Michael Morrison, Paul Novitski, Tia Gustaff Rayl which I bought some time ago, impressed by its sheer bulk but which I am unlikely ever to read let alone review!
Learning new programming languages is easy in some senses: it’s generally straightforward to get something to happen simply because core syntax is common across many languages. The only seriously different language I’ve used is Haskell. The difficulty with programming languages is idiom, the parallel is with human languages: the barrier to making yourself understood in a language is low, but to speak fluently and elegantly needs a higher level of understanding which isn’t simply captured in grammar. Programming languages are by their nature flexible so it’s quite possible to write one in the style of another – whether you should do this is another question.
My first programming language was BASIC, I suspect I speak all other computer languages with a distinct BASIC accent. As an aside, Edsger Dijkstra has said:
[…] the teaching of BASIC should be rated as a criminal offence: it mutilates the mind beyond recovery.
– so perhaps there is no hope for me.
JavaScript has always felt to me a toy language: it originates in a web browser and relies on HTML to import libraries but nowadays it is available on servers in the form of node.js, has a wide range of mature libraries and is very widely used. So perhaps my prejudices are wrong.
The central idea of JavaScript: The Good Parts is to present an ideal subset of the language, the Good Parts, and ignore the less good parts. The particular bad parts of which I was glad to be warned:
- JavaScript arrays aren’t proper arrays with array-like performance, they are weird dictionaries;
- variables have function not block scope;
- unless declared inside a function variables have global scope;
- there is a difference between the equality == and === (and similarly the inequality operators). The short one coerces and then compares, the longer one does not, and is thus preferred.
I liked the railroad presentation of syntax and the section on regular expressions is good too.
Elsewhere Crockford has spoken approvingly of CoffeeScript which compiles to JavaScript but is arguably syntactically nicer, it appears to hide some of the bad parts of JavaScript which Crockford identifies.
If you are new to JavaScript but not to programming then this is a good book which will give you a fine start and warn you of some pitfalls. You should be aware that you are reading about Crockford’s ideal not the code you will find in the wild.
Apr 17 2013
Book review: R in Action by Peter Harrington

This post was first published at ScraperWiki.
This is a review of Robert I. Kabacoff’s book R in Action which is a guided tour around the statistical computing package, R.
My reasons for reading this book were two-fold: firstly, I’m interested in using R for statistical analysis and visualisation. Previously I’ve used Matlab for this type of work, but R is growing in importance in the data science and statistics communities; and it is a better fit for the ScraperWiki platform. Secondly, I feel the need to learn more statistics. As a physicist my exposure to statistics is relatively slight – I’ve wondered why this is the case and I’m eager to learn more.
In both cases I see this book as an atlas for the area rather than an A-Z streetmap. I’m looking to find out what is possible and where to learn more rather than necessarily finding the detail in this book.
R in Action follows a logical sequence of steps for importing, managing, analysing, and visualising data for some example cases. It introduces the fundamental mindset of R, in terms of syntax and concepts. Central of these is the data frame – a concept carried over from other statistical analysis packages. A data frame is a collection of variables which may have different types (continuous, categorical, character). The variables form the columns in a structure which looks like a matrix – the rows are known as observations. A simple data frame would contain the height, weight, name and gender of a set of people. R has extensive facilities for manipulating and reorganising data frames (I particularly like the sound of melt in the reshape library).
R also has some syntactic quirks. For example, the dot (.) character, often used as a structure accessor in other languages, is just another character as far as R is concerned. The $ character fulfills a structure accessor-like role. Kabacoff sticks with the R user’s affection for using <- as the assignment operator instead of = which is what everyone else uses, and appears to work perfectly well in R.
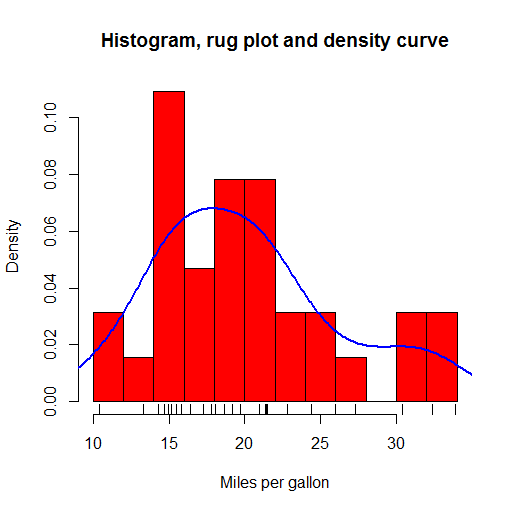
R offers a huge range of plot types out-of-the-box, with many more a package-install away (and installing packages is a trivial affair). Plots in the base package are workman-like but not the most beautiful. I liked the kernel density plots which give smoothed approximations to histogram plots and the rug plots which put little ticks on the axes to show where the data in the body of that plot fall. These are all shown in the plot below, plotted from example data included in R.
The ggplot2 package provides rather more beautiful plots and seems to be the choice for more serious users of R.
The statistical parts of the book cover regression, power analysis, methods for handling missing data, group comparison methods (t-tests and ANOVA), and principle component and factor analysis, permutation and bootstrap methods. I found it a really useful survey – enough to get the gist and understand the principles with pointers to more in-depth information.
One theme running through the book, is that there are multiple ways of doing almost anything in R, as a result of its rich package ecosystem. This comes to something of a head with graphics in the final section: there are 4 different graphics systems with overlapping functionality but different syntax. This collides a little with the Matlab way of doing things where there is the one true path provided by Matlab alongside a fairly good, but less integrated, ecosystem of user-provided functionality.
R is really nice for this example-based approach because the base distribution includes many sample data sets with which to play. In addition, add-on packages often include sample data sets on which to experiment with the tools they provide. The code used in the book is all relatively short; the emphasis is on the data and analysis of the data rather than trying to build larger software objects. You can do an awful lot in a few lines of R.
As an answer to my statistical questions: it turns out that physics tends to focus on Gaussian-distributed, continuous variables, while statistics does not share this focus. Statistics is more generally interested in both categorical and continuous variables, and distributions cannot be assumed. For a physicist, experiments are designed where most variables are fixed, and the response of the system is measured as just one or two variables. Furthermore, there is typically a physical theory with which the data are fitted, rather than a need to derive an empirical model. These features mean that a physicist’s exposure to statistical methods is quite narrow.
Ultimately I don’t learn how to code by reading a book, I learn by solving a problem using the new tool – this is work in progress for me and R, so watch this space! As a taster, just half a dozen lines of code produced the appealing visualisation of twitter profiles shown below:
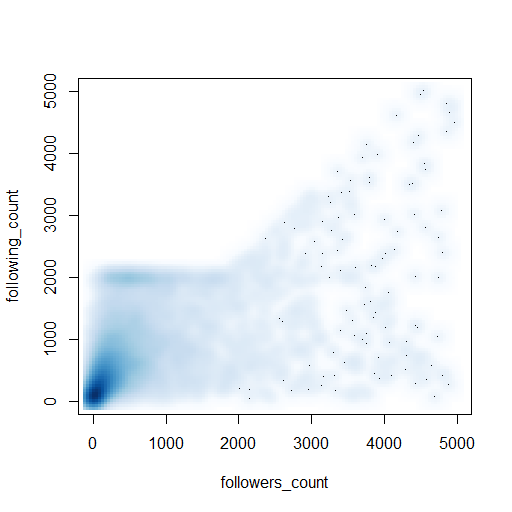
(Here’s the code: https://gist.github.com/IanHopkinson/5318354)
Apr 17 2013
Book review: Machine Learning in Action by Peter Harrington

This post was first published at ScraperWiki.
Machine learning is about prediction, and prediction is a valuable commodity. This sounds pretty cool and definitely the sort of thing a data scientist should be into, so I picked up Machine Learning in Action by Peter Harrington to get an overview of the area.
Amongst the examples covered in this book are:
- Given that a customer bought these items, what other items are they likely to want?
- Is my horse likely to die from colic given these symptoms?
- Is this email spam?
- Given that these representatives have voted this way in the past, how will they vote in future?
In order to make a prediction, machine learning algorithms take a set of features and a target for a training set of examples. Once the algorithm has been trained, it can take new feature sets and make predictions based on them. Let’s take a concrete example: if we were classifying birds, the birds’ features would include the weight, size, colour and so forth and the target would be the species. We would train the algorithm on an initial set of birds where we knew the species, then we would measure the features of unknown birds and submit these to the algorithm for classification.
In this case, because we know the target – a species of bird – the algorithms we use would be referred to as “supervised learning.” This contrasts “unsupervised learning,” where the target is unknown and the algorithm is seeking to make its own classification. This would be equivalent to the algorithm creating species of birds by clustering those with similar features. Classification is the prediction of categories (i.e. eye colour, like/dislike), alternatively regression is used to predict the value of continuous variables (i.e. height, weight).
Machine learning in Action is divided into four sections that cover key elements and “additional tools” which includes algorithms for dimension reduction and MapReduce – a framework for parallelisation. Dimension reduction is the process of identifying which features (or combination of features) are essential to a problem.
Each section includes Python code that implements the algorithms under discussion and these are applied to some toy problems. This gives the book the air of Numerical Recipes in FORTRAN, which is where I cut my teeth on numerical analysis. The mixture of code and prose is excellent for understanding exactly how an algorithm works, but its better to use a library implementation in real life.
The algorithms covered are:
- Classification – k-Nearest Neighbours, decision trees, naive Bayes, logistic regression, support vector machines, and AdaBoost;
- Regression – linear regression, locally weighted linear regression, ridge regression, tree-based regression;
- Unsupervised learning – k-means clustering, apriori algorithm, FP-growth;
- Additional tools – principle component analysis and singular value decomposition.
Prerequisites for this book are relatively high: it assumes fair Python knowledge, some calculus, probability theory and matrix algebra.
I’ve seen a lot of mention of MapReduce without being clear what it was. Now I am more clear: it is a simple framework for carrying out parallel computation. Parallel computing has been around quite some time, the problem has always been designing algorithms that accommodate parallelisation (i.e. allow problems to be broken up into pieces which can be solved separately and then recombined). MapReduce doesn’t solve this problem but gives a recipe for what is required to run on commodity compute cluster.
As Harrington says: do you need to run MapReduce on a cluster to solve your data problem? Unless you are an operation on the scale of Google or Facebook then probably not. Current, commodity desktop hardware is surprisingly powerful particularly when coupled with subtle algorithms.
This book works better as an eBook than paper partly because the paper version is black and white and some figures require colour but the programming listings are often images and so the text remains small.
Apr 02 2013
Book review: Data Visualization: a successful design process by Andy Kirk

This post was first published at ScraperWiki.
My next review is of Andy Kirk’s book Data Visualization: a successful design process. Those of you on Twitter might know him as @visualisingdata, where you can follow his progress around the world as he delivers training. He also blogs at Visualising Data.
Previously in this area, I’ve read Tufte’s book The Visual Display of Quantitative Information and Nathan Yau’s Visualize This. Tufte’s book is based around a theory of effective visualisation whilst Visualize This is a more practical guide featuring detailed code examples. Kirk’s book fits between the two: it contains some material on the more theoretical aspects of effective visualisation as well as an annotated list of software tools; but the majority of the book covers the end-to-end design process.
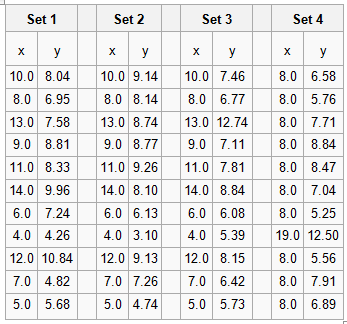
Data Vizualisation introduced me to Anscombe’s Quartet. The Quartet is four small datasets, eleven (x,y) coordinate pairs in each. The Quartet is chosen so the common statistical properties (e.g. mean values of x and y, standard deviations for same, linear regression coefficients) for each set are identical, but when plotted they look very different. The numbers are shown in the table below.
Plotted they look like this:
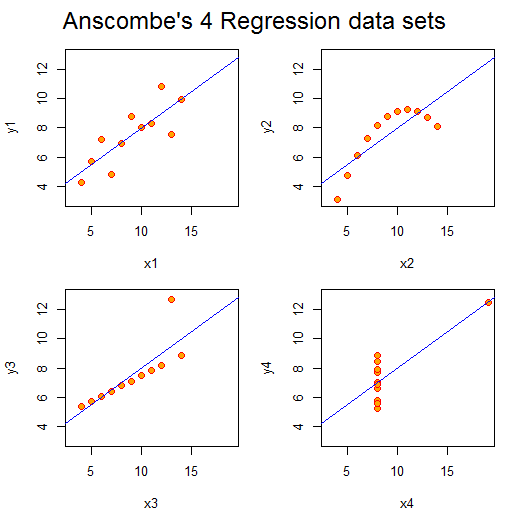 Aside from set 4, the numbers look unexceptional. However, the plots look strikingly different. We can easily classify their differences visually, despite the sets having the same gross statistical properties. This highlights the power of visualisation. As a scientist, I am constantly plotting the data I’m working on to see what is going on and as a sense check: eyeballing columns of numbers simply doesn’t work. Kirk notes that the design criteria for such exploratory visualisations are quite different from those highlighting particular aspects of a dataset, more abstract “data art” presentations, or a interactive visualisations prepared for others to use.
Aside from set 4, the numbers look unexceptional. However, the plots look strikingly different. We can easily classify their differences visually, despite the sets having the same gross statistical properties. This highlights the power of visualisation. As a scientist, I am constantly plotting the data I’m working on to see what is going on and as a sense check: eyeballing columns of numbers simply doesn’t work. Kirk notes that the design criteria for such exploratory visualisations are quite different from those highlighting particular aspects of a dataset, more abstract “data art” presentations, or a interactive visualisations prepared for others to use.
In contrast to the books by Tufte and Yau, this book is much more about how to do data visualisation as a job. It talks pragmatically about getting briefs from the client and their demands. I suspect much of this would apply to any design work.
I liked Kirk’s “Eight Hats of data visualisation design” metaphor; which name the skills a visualiser requires: Initiator, Data Scientist, Journalist, Computer Scientist, Designer, Cognitive Scientist, Communicator and Project Manager. In part, this covers what you will require to do data visualisation, but it also gives you an idea of whom you might turn to for help – someone with the right hat.
The book is scattered with examples of interesting visualisations, alongside a comprehensive taxonomy of chart types. Unsurprisingly, the chart types are classified in much the same way as statistical methods: in terms of the variable categories to be displayed (i.e. continuous, categorical and subdivisions thereof). There is a temptation here though: I now want to make a Sankey diagram… even if my data doesn’t require it!
In terms of visualisation creation tools, there are no real surprises. Kirk cites Excel first, but this is reasonable: it’s powerful, ubiquitous, easy to use and produces decent results as long as you don’t blindly accept defaults or get tempted into using 3D pie charts. He also mentions the use of Adobe Illustrator or Inkscape to tidy up charts generated in more analysis-oriented packages such as R. With a programming background, the temptation is to fix problems with layout and design programmatically which can be immensely difficult. Listed under programming environments is the D3 Javascript library, this is a system I’m interested in using – having had some fun with Protovis, a D3 predecessor.
Data Visualization works very well as an ebook. The figures are in colour (unlike the printed book) and references are hyperlinked from the text. It’s quite a slim volume which I suspect compliments Andy Kirk’s “in-person” courses well.
Mar 26 2013
Book review: The Dinosaur Hunters by Deborah Cadbury
 A rapid change of gear for my book reviewing: having spent several months reading “The Eighth Day of Creation” I have completed “The Dinosaur Hunters” by Deborah Cadbury in only a couple of weeks. Is this a bad thing? Yes, and no – it’s been nice to read a book that rattles along at a good pace, is gripping and doesn’t have me leaping to make notes at every page – the downside is that I feel I have consumed a literary snack rather than a meal.
A rapid change of gear for my book reviewing: having spent several months reading “The Eighth Day of Creation” I have completed “The Dinosaur Hunters” by Deborah Cadbury in only a couple of weeks. Is this a bad thing? Yes, and no – it’s been nice to read a book that rattles along at a good pace, is gripping and doesn’t have me leaping to make notes at every page – the downside is that I feel I have consumed a literary snack rather than a meal.
The Dinosaur Hunters covers the initial elucidation of the nature of large animal fossils, principally of dinosaurs, from around the beginning of the 19th century to just after the publication of Darwin’s “Origin of the Species” in 1859. The book is centred around Gideon Mantell (1790-1852) who first described the Iguanodon and was an expert in the geology of the Weald, at the same time running a thriving medical practice in his home town of Lewes. Playing the part of Mantell’s nemesis is Richard Owen (1804-1892), who formally described the group of species, the Dinosauria, and was to be the driving force in the founding of the Natural History Museum in the later years of the 19th century. Smaller parts are played by Mary Anning (1799-1847), fossil collector based in Lyme Regis; William Buckland (1784-1856) who described Megalosaurus – the first of the dinosaurs and spent much of his life trying to reconcile his Christian faith with new geological findings; George Cuvier (1769-1832) the noted French anatomist who related fossil anatomy to modern animal anatomy and identified the existence of extinctions (although he was a catastrophist who saw this as evidence of different epochs of extinction rather than a side effect of evolution); Charles Lyell (1897-1875) a champion of uniformitarianism (the idea that the modern geology is the result of processes visible today continuing over great amounts of time); Charles Darwin (1809-1882) who really needs no introduction, and Thomas Huxley (1825-1895) a muscular proponent of Darwin’s evolutionary theory.
For me a recurring theme was that of privilege and power in science, often this is portrayed as something which disadvantaged women but in this case Mantell is something of a victim too, as was William Smith as described in “The Map that Changed the World”. Mantell was desperate for recognition but held back by his full-time profession as a doctor in a minor town and his faith that his ability would lead automatically to recognition. Owen, on the other hand, with similar background (and prodigious ability) went first to St Bartholomew’s hospital and then the Royal College of Surgeon’s where he appears to have received better patronage but in addition was also brutal and calculating in his ambition. Ultimately Owen over-reached himself in his scheming, and although he satisfied his desire to create a Natural History Museum, in death he left little personal legacy – his ability trumped by his dishonesty in trying to obliterate his opponents.
From a scientific point of view the thread of the book is from the growing understanding of stratigraphy i.e. the consistent sequence of rock deposits through Great Britain and into Europe; the discovery of large fossil animals which had no modern equivalent; the discovery of an increasing range of these prehistoric remnants each with their place in the stratigraphy and the synthesis of these discoveries in Darwin’s theory of evolution. Progress in the intermediate discovery of fossils was slow because in contrast to the the early fossils of marine species such as icthyosaurus and plesiosaurus which were discovered substantially intact later fossils of large land animals were found fragmented in Southern England, which made identifying the overall size of such species and even the numbers of species present in your pile of fossils difficult.
These scientific discoveries collided with a social thread which saw the clergy deeply involved in scientific discovery at the beginning, becoming increasingly discomforted with the account of the genesis of life in Scripture being incompatible with the findings in the stone. This ties in with a scientific community trying to make their discoveries compatible with Scripture and what they perceived to be the will of God with the schism between the two eventually coming to a head by the publication of Darwin’s Origin of Species.
Occasionally the author drops into a bit of first person narration which I must admit to finding a bit grating, perhaps because for people long dead it is largely inference. I’d have been very happy to have chosen this book for a long journey or a holiday, I liked the wider focus on a story rather than an individual.
References
About

I've worked as a scientist for the last 30 years, at various universities, a large home and personal care company, a startup in Liverpool called The Sensible Code Company (formerly ScraperWiki Ltd), GBG and now as a consultant in data science.
I write about:
* the books I have read, typically science and history (or both), partly as a reminder to myself and partly as a review;
* science, things I have done or things I find interesting;
* technology, programming and gadgets;
politics, and current affairs;
* ...and other stuff as it takes my fancy - holidays, photographs and things I want to remember.