This review was first published at ScraperWiki.
My unstoppable reading continues, this time I’ve polished off The Tableau 8.0 Training Manual: From Clutter to Clarity by Larry Keller. This post is part review of the book, and part review of Tableau.
Tableau is a data visualisation application which grew out of academic research on visualising databases. I’ve used Tableau Public a little bit in the past. Tableau Public is a free version of Tableau which only supports public data i.e. great for playing around with but not so good for commercial work. Tableau is an important tool in the business intelligence area, useful for getting a quick view on data in databases and something our customers use, so we are interested in providing Tableau integration with the ScraperWiki platform.
The user interface for Tableau is moderately complex, hence my desire for a little directed learning. Tableau has a pretty good set of training videos and help pages online but this is no good to me since I do a lot of my reading on my commute where internet connectivity is poor.
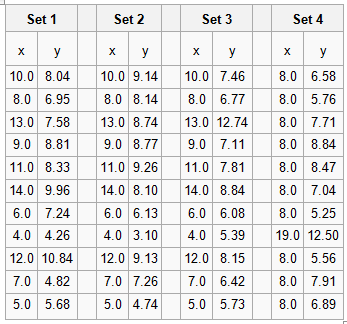
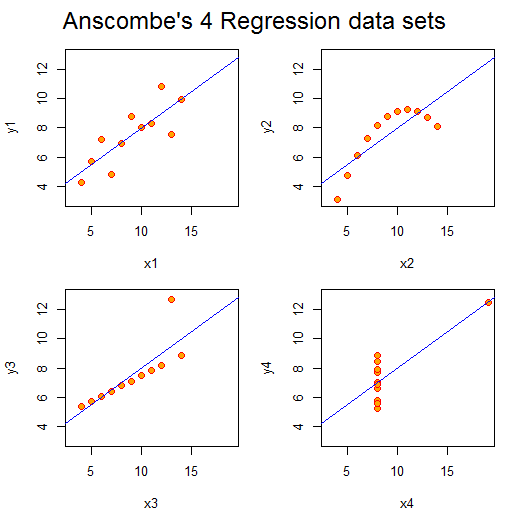
Tableau is rather different to the plotting packages I’m used to using for data analysis. This comes back to the types of data I’m familiar with. As someone with a background in physical sciences I’m used to dealing with data which comprises a couple of vectors of continuous variables. So for example, if I’m doing spectroscopy then I’d expect to get a pair of vectors: the wavelength of light and the measured intensity of light at those wavelengths. Things do get more complicated than this, if I were doing a scattering experiment then I’d get an intensity and a direction (or possibly two directions). However, fundamentally the data is relatively straightforward.
Tableau is crafted to look at mixtures of continuous and categorical data, stored in a database table. Tableau comes with some sample datasets, one of which is sales data from superstores across the US which illustrates this well. This dataset has line entries of individual items sold with sale location data, product and customer (categorical) data alongside cost and profit (continuous) data. It is possible to plot continuous data but it isn’t Tableau’s forte.
Tableau expects data to be delivered in “clean” form, where “clean” means that spreadsheets and separated value files must be presented with a single header line with columns which contain data all of the same type. Tableau will also connect directly to a variety of databases. Tableau uses the Microsoft JET database engine to store it’s data, I know this because for some data unsightly wrangling is required to load data in the correct format. Once data is loaded Tableau’s performance is pretty good, I’ve been playing with the MOT data which is 50,000,000 or so lines, which for the range of operations I tried turned out to be fairly painless.
Turning to Larry Keller’s book, The Tableau 8.0 Training Manual: From Clutter to Clarity, this is one of few books currently available relating to the 8.0 release of Tableau. As described in the title it is a training manual, based on the courses that Larry delivers. The presentation is straightforward and unrelenting; during the course of the book you build 8 Tableau workbooks, in small, explicitly described steps. I worked through these in about 12 hours of screen time, and at the end of it I feel rather more comfortable using Tableau, if not expert. The coverage of Tableau’s functionality seems to be good, if not deep – that’s to say that as I look around the Tableau interface now I can at least say “I remember being here before”.
Some of the Tableau functionality I find a bit odd, for example I’m used to seeing box plots generated using R, or similar statistical package. From Clutter to Clarity shows how to make “box plots” but they look completely different. Similarly, I have a view as to what a heat map looks like and the Tableau implementation is not what I was expecting.
Personally I would have preferred a bit more explanation as to what I was doing. In common with Andy Kirk’s book on data visualisation I can see this book supplementing the presented course nicely, with the trainer providing some of the “why”. The book comes with some sample workbooks, available on request – apparently directly from the author whose email response time is uncannily quick.