
Ian Hopkinson
Author's posts
Jan 06 2025
Rosetta Stone – Rust
In an earlier blog post I explained the motivation for a series of “Rosetta Stone” posts which described the ecosystem for different programming languages. This post covers Rust, the associated GitHub repository with some minimal code is here. This blog post aims to provide some discussion around technology choices whilst the GitHub repository provides details of what commands to execute and a minimal example project.
I became interested in Rust because a number of new tools such as uv and ruff for the Python ecosystem are written in Rust. It’s fair to say there has been a buzz around the language in programming circles for some years.
About Rust
Rust started out as a personal project by Graydon Hoare, an employee of Mozilla, in 2006. It was adopted by Mozilla in 2009 and in 2012 the first public release was made. It was originally designed with a focus on memory management and memory safety. It stands with C and assembly as the only languages supported in the development of the Linux kernel. I read the The Rust Programming Language book recently, the distinguishing feature of Rust is the borrow checker and ownership model which is what gives it strong memory safety credentials.
Rust is named for the rust fungi, not the corrosion of iron but it seems few people realise this!
Rust currently ranks 13th on the TIOBE index but has been regularly voted the most admired language on the Stackoverflow rankings.
How is the language defined?
The home for the Rust language is here. Rust evolves through an RFC (request for comments) process, which can be found in the Rust RFC Book. Currently there is no formal specification for the language but there is an exercise to write one.
New versions of the language are released every 6 week (see here). Breaking changes can be introduced in editions (once every 3 years with the next edition, 2024, due in February 2025) but upgrading between editions is optional and there are tools to support version migrations. For more about the edition process see here.
There is a roadmap for the 2024 edition (see here) and presumably once that is released the next roadmap will be developed.
Rust Compilers
The Rust compiler is rustc, there are some alternatives but they are experiments rather than production systems. Typically rustc is invoked with the cargo package manager, see below. My first impression was that the compiler provided really good error messages.
Details of installation can be found here in the accompanying GitHub repository. Installing the whole Rust toolchain is ridiculously simple.
Package management
cargo is the Rust package manager, it is also typically used to compile code to produce a “crate” which may be a binary or library.
Rather neatly invoking cargo to produce a new package also creates a new Git repository with the appropriate layout:
cargo new hello_world --bin
This generates a cargo.toml file which defines the project and dependencies, and on compile a cargo.lock file is produced which specifies exactly the versions of all the dependences. This parallels the NPM system for JavaScript/TypeScript. There is also a --lib flag which generates a layout for a library package. In practice this is just a starting point, your code may include both binaries and libraries for which you will need to edit the cargo.toml file. However, this cargo new process reflects how I would start a project in Python.
The standard library is here, there are no built-in CSV or JSON libraries – regular readers will recall I use this as a measure of a language’s completeness since my favoured language, Python, has them! Others may have different opinions.
Third party Rust crates can be found on the crate registry.
Virtual environments
Rust does not require virtual environments since cargo fetches the appropriate packages on compile, it uses a local cache of packages but this is a true cache – if the version of a package is not in the cache then it is fetched.
Project layout for package publication
cargo new generates a minimal project layout. More generally the conventional project layout is shown below (see here) when code is compiled a target directory is created for the compiled code.
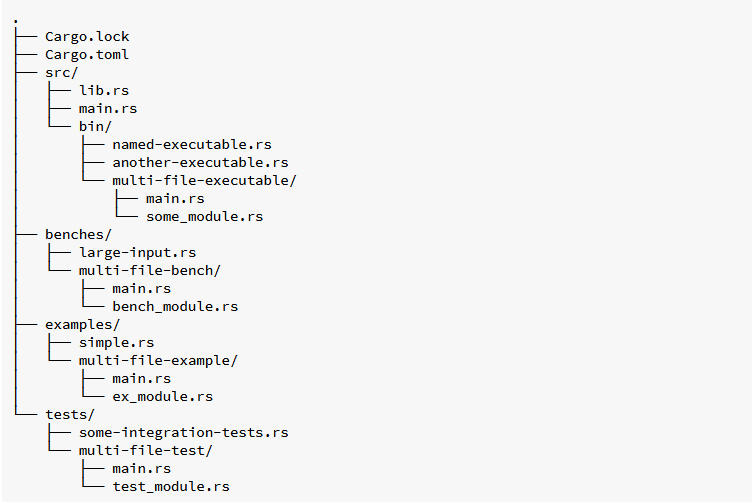
It is rather nice having a mandated project layout!
Testing
A testing framework is built-in and a skeleton test is included when a --lib project is created by cargo The tests look like this:

This is essentially a unit test and the intention in Rust is that the unit tests sit next to the functions which they test, in Python unit tests tend to be separated into tests directory. In a Rust project the tests directory holds integration tests. There is a third type of test, doctests which are embedded in the comments intended for documentation.
All three types of test can be run with cargo test.
The built-in test functionality does not include features such as mocks or parameterized tests but there are third party crates to provide this functionality.
Static analysis and formatting tools
Clippy is the built-in linter, used in addition to rustfmt, the formatter. The are invoked using cargo with cargo fmt and cargo clippy. As a compiled language the compiler provides static analysis too. I would not expect alternatives to clippy or rustfmt to gain much traction since these appear to be the “official” tools.
Documentation Generation
rustdoc is the standard documentation generator tool (see here), working from comments in code and invoked using cargo doc. It feels to me that there is scope for alternatives to rustdoc although perhaps I am mixing up the documentation generation engine with the standards for code comments for documentation which have arisen in Python.
Wrapping up
I was struck by how everything is pretty much built-in for Rust; compiling, packaging, testing, formatting, and linting. All of these tools can be driven from the package management tool, cargo. It is almost like the design team was trying to make the job of writing this post as easy as possible! In writing Rust code in associated with this post I found the built-in test framework missing features (like mocks and parameterization which I’m used to in Python), similarly the documentation system is quite simple so perhaps in time alternatives will start to predominate.
My “home” language of Python has acquired these features over a long period of time, utilizing third party libraries and tools that eventually became de facto standards.
It would be nice to make a comparison with Go which occupies a similar space in programming as a relatively recent arrival with what I believe is a similarly full tool suite.
I welcome comments, probably best on Mastodon where you can find me here.
Dec 30 2024
Review of the year: 2024

I am now recovering from my long COVID, I can get out and about more now without getting exhausted – I even went on holiday to Rhosneigr for a week in the summer! I have fewer days feeling absolutely awful. This was in part a result of the local long COVID clinic, the instructor for the long COVID exercise classes I attended mentioned that some long COVID sufferers had issues with “mast cell activation syndrome” (MCAS) which can be addressed by dietary changes – essentially a low histamine diet. This has worked for me although I can’t drink alcohol or eat mature cheeses which has been a bit of a blow.
I have been working with the Humanitarian Data Exchange for UNOCHA for the past year which I have really enjoyed, that contract comes to an end shortly so I will be looking for freelance work. I’m also thinking more seriously about retiring. As a result of having paid work I felt able to spend freely, I bought myself a new guitar (an Epiphone Les Paul Standard gold top) and an electric bike (a Rayleigh Motus) – the electric bike has been brilliant and helped me get out and about. I think this is part of the reason I can think about retiring, other middle aged men would buy a Gibson Les Paul and a motorbike for x10 the cost of my purchases!

This year I reviewed 13 books. I started the year with Her Space, Her Time by Shohini Ghose which was about a history of women in physics, generally astrophysics and cosmology in the late 19th and 20th centuries. I followed this with A Philosophy of Software Design by John Ousterhout which provided an alternative view to how best to design software. Also in this theme was Beautiful Code edited by Andy Oram & Greg Wilson, an edited volume of essays on pieces of code that their authors were particularly pleased with. In the computing theme I also read The Rust Programming Language by Steve Klabnik and Carol Nichols – I’m currently learning Rust. I actually read this book online which is a novelty for me.
My favourite book of the year was An Immense World by Ed Yong this is about animal senses, I picked it up slightly reluctantly thinking that there wasn’t much to say about the five senses and that everything was pretty well known by now. I was wrong on both accounts! I enjoy Yong’s writing, this combined with the subject matter made it my favourite.
I had a bit of an Alice Roberts binge. I read Ancestors, about burials in prehistoric Britain, a few years ago. This year I read Buried and Crypt which are partner volumes to Ancestors which cover burials in the first millennium and the first half of the second millennium respectively. Buried has a secondary theme of migration and Crypt of disease and injury. I also read Anatomical Oddities by Alice Roberts – I must admit this one didn’t really appeal to me. It is a collection of anatomical illustrations with some commentary, Roberts is a very fine illustrator but the text for the book was incoherent.
In the past I have mainly read on the history of science with most material relating to the 15th century and onwards. Roberts’ books got me interested in the earlier history of Britain. I started with Britain BC by Francis Pryor which covers Britain prior to the Roman invasion. Echolands by Duncan MacKay covers Boudica’s revolt against the Roman’s in 60-61AD, it’s a sort of history/travelogue combination which I found very engaging. Roman Britain – A New History by Guy de la Bédoyère is a beautiful, encyclopaedic coffee table book which covers the whole of the Roman occupation of Britain. I am now interested in the late Iron Age coinage in Britain.
To finish with a couple of books which didn’t follow any theme. I read Daphne Draws Data by Cole Nussbaumer Knaflic which is a book about data visualization for children – I reviewed this at the request of the author. I rather enjoyed it and hope to be able to borrow some of the illustrations for my own presentations. Sound tracks by Graeme Lawson is a history of musical instruments via archaeological artefacts. What struck me here is how little of musical instruments survives (usually only metal parts), and also how long sophisticated flutes and pipes have been in existence.
I took part in the Chester mid-summer parade, as a pirate – as I have done for the last few years – I was able to sit down a lot of the time which was a big help.

Our son is now at online school (Minerva’s Virtual Academy), he is settling in well but getting to this point was not voluntary and was traumatic.
We’re looking forward to a new year of improving health, semi-retirement and lower stress education!
Dec 12 2024
Book review: The Rust Programming Language by Steve Klabnik and Carol Nichols

My next review is a small departure, it is for The Rust Programming Language by Steve Klabnik and Carol Nichols but rather than buy the physical book I read this interactive version, which has quizzes and embedded, runnable code.
The Rust programming language is the target for my next Rosetta Stone blog post which identifies all the tooling for a language. For Rust these tools (the compiler, formatter, linter, package management and automated documentation) are pretty much all “built-in” so my job will be easy. The challenge in this case has been learning the language since I try to write a little code for the Rosetta Stone posts to demonstrate what I’ve learned.
Rust is a relatively new language, very highly regarded amongst developers and one of only two approved for developing Linux. Its focus is on “safety” and speed. It has been used to make new, highly performant tools for the Python ecosystem, like ruff and uv, which is how I came to know of it.
For a Python programmer Rust does not look alien in the way that Haskell and Lisp do; admittedly it uses curly braces for scoping, is strongly-typed and supports pointers and references which are not features of Python but are common in other languages.
To me it feels like C but with some object-oriented features; the authors talk explicitly about it having features of functional languages including use of the Option value which contains something or nothing, the compiler enforces the handling of nothing. I think I might start using this more explicitly in Python which allows type-hinting to indicate an Option-like value. The other explicitly referenced functional feature is the use of closures, in Python closures are functions defined within functions or anonymous / lambda functions whilst in Rust they seem to be closer to functions passed as arguments to other functions.
Rust makes what seems an odd distinction between functions and macros in its standard library. Macros are identified with an exclamation mark, for example println! As I understand this is because a macro is implemented using code generation at runtime which allows the developer to supply, for example, a variable number of arguments to println! which would not be possible for a function println. Python doesn’t make this distinction and is very permissive in the arguments that a function can take, allowing both position and keyword arguments of variable number.
I was struck by the way that different languages use the same word for different things. For example in Rust a struct is both a data container but can also carry methods in the way that “classes” in other languages do. In Python an enum is a closed list of values but in Rust those values can have user-defined associated values so that an enum for IP address protocols can contain V4 and V6 (as it would in Python) but in addition it can hold an actual IP address associated with each entry in the enumeration.
My understanding is that Rust is considered an object-oriented language by some but not all. In practical terms the only object-oriented feature missing is inheritance although this can be approximated by the use of generics and traits.
Since I have scarcely used pointers and references in 40 years of programming I found these concepts a bit challenging but I have made progress in my understanding through reading this book. Excited by this new found understanding I was then confused by Rust’s ownership model! Ownership and borrowing are the big, unique conceptual features of Rust. The aim of ownership is to rigorously ensure that code is safe – no writing past the end of arrays, or dereferencing null points. It also means that the performance hit of a garbage collector is not required, this task is pretty much entirely handled at compile time by the borrow checker. The strong ownership model makes concurrent programming easier too.
In trying to understand ownership and borrowing I found some useful tools, the best entry point was the BORIS tool by Christian Schott which lists other visualization tools including the Aquascope tool used in this book. I found the first such tool in RustViz which is used in teaching, it needs the user to put annotations into the code rather than working out the annotations itself. I also read this article by Chris Morgan.
As language books go, this one is pretty readable, and I found the built-in quizzes handy, if only to illustrate my ignorance particularly of the ownership and borrowing model. I think for my next technical book I might read Category Theory for Programmers by Bartosz Milewski. I have felt when applying type-hints to Python, and learning Rust and Haskell that I was missing out by not understanding at least the basics of category theory.
I enjoyed this book and the format worked pretty well for me, although I need to find a way of reading online content like this in more comfort. I’m keen to give Rust a go now!
Nov 17 2024
Book review: Roman Britain – A New History by Guy de la Bédoyère

Following on from my previous review of Echolands by Duncan MacKay on Boudica’s revolt against the Roman occupiers of Britain, this review is of Roman Britain: A New History by Guy de la Bédoyère. Roman Britain has a much wider scope than Echolands covering the whole period of Roman influence in Britain from Caesar’s abortive invasions in 55 and 54BC through to the period after the Roman’s left Britain in 410AD. This is a larger format book with illustrations and photographs on virtually every page.
The book starts with three chapters on the timeline of Roman Britain covering the pre-invasion period, the extended conquest and the later period. Eight chapters follow on different themes: governing Britain, military installations, towns in Roman Britain, industry, commerce and production, the countryside and villas, people and places of roman Britain, religion in Roman Britain and the aftermath.
Britain was know to the Greeks as far back as the 4th century BC, and there was trade in tin from Britain from that time. By the middle of the 2nd century BC ornate burials were being found in Britain containing imported goods, and coinage was starting to be found. Hengistbury Head, where my father lived in his retirement, was an important trade port in this period. This tells us that Britain was not unknown to the outside world when Caesar made his invasion attempts in 55BC and 54BC. These were unsuccessful in the immediate sense but over the intervening years to the invasion proper in 43AD there was a gradual Romanisation of the upper echelons of British society, and increased trade.
Both Caesar’s abortive invasion, and Claudius’s successful invasion in 43AD were driven by politics in Rome, military success were a credit to an Emperor. British politics may well have played a part: Cunobelinus, king of a large chunk of Britain, died in 43AD and the resulting uncertainty over succession was a good opportunity to invade. Claudius’s invasion succeeded because the Roman army were a very efficient, well-equipped military force and their opposition was divided with some on the British side likely supporting the Romans.
The Romans spread to a line linking Lincoln and Exeter by 47AD, and by the end of the 1st century they had reached the limits of Wales and the far North of Scotland. Over the next 50 years there was some consolidation but by 150AD the Roman’s had reached the geographic limit of their occupation of Britain. It seems that the South-East of Britain became fairly well Romanised with villas and towns in the Roman style. North and West of the 47AD frontier life seemed to continue more in the manner of the Iron Age but for the addition of Roman garrisons and forts with related trade and industries.
Most of what we know of Roman life in Britain is based on the inscriptions left by the military, on tombstones and dedications of building works. There are limited number of wooden writing tablets, discovered at Vindolanda by Hadrian’s Wall and in London, which provide a fascinating insight into daily life, trade and interpersonal relationships. The early period of the occupation is discussed in Tacitus’s writings, as well as some other fragments.
We get a very small sample of daily life from from archaeology, only about 0.01% of all deaths are represented in burials and, assuming villas had 40 occupants each, homes for only about 0.01% are known.
Much of the rest of our understanding seems to come from recognising that Britain was being run like any other Roman province and extrapolating across archaeological and historical writings from all over the empire. Roman’s had firm ideas about which people could hold which positions (qualified by property), and Roman towns had a specific set of amenities according to their official type. Britain was seen as a troublesome province and had quite senior governors who typically only had a short tenure – some went on to become Emperor.
The Roman’s seemed to have respected the British as traders, seeing them as taking on Roman ways in this regard. Agriculture was important, and there is a lot of evidence of lead production – unlike iron, lead tends to survive quite well. Coinage was only minted in Britain from the late third century – it would not be used so heavily until the 17th.
There is limited evidence for the health and ethnicity of the Roman Britons, they seem to have increased dental issues. There was certainly the idea of branded medications, particularly for eye conditions. It isn’t clear whether there was a patent system. It is certain that Roman soldiers came from around the Empire but identifying them is hard since typically they Romanised their names.
Most of the writing we find the Roman period relates to religion (shrines, tombstones, altars). For a large part of the Roman period people worshipped hybrid Gods – amalgams of Roman Gods with local pagan deities or even from elsewhere in the Roman empire. Later the Christian church became established – we have written evidence of a church hierarchy from 314AD.
From the beginning of the third century AD the Roman empire was beginning to split up. Rome finally withdrew support for the military occupation of Britain in 410AD. This had an immediate economic impact because there was no longer new coinage coming into the country, or military salaries to spend. Physically Roman buildings decayed over a period of 150 years or so with the now non-Roman occupants no longer having the will or skill to repair them. We can mark the complete end of practical Roman influence with the invasion of the Anglo-Saxons in 577AD although we see the marks of the Roman occupation even now in our landscape and language.
Roman Britain finishes with a chronology and a guide to visiting Roman sites in Britain, I feel in this section insufficient attention is paid to my home town of Chester!
This is a beautiful book, and rather readable.
Oct 05 2024
Book review: Echolands by Duncan MacKay

One book leads to another, after reading about prehistoric Britain I was interested in what came next – the Romans. Someone on social media suggested Echolands by Duncan MacKay subtitled A Journey in Search of Boudica. This is an apt description, the book is part travelogue, part history book. MacKay describes his journey following the path of Boudica to Colchester, London, Verulamium and to a final Great Battle with Paulinus, the Roman governor of Britain at the time. He travels variously by car, foot and bicycle. Initially I was sceptical of this style but it is rather compelling – the journey acts as a kind of mnemonic map for the historical facts conveyed.
Britain’s written history starts with Caesar’s expeditions in 54BC and 55BC. It was written not by the British but the Romans. Caesar did not conqueror any territory in Britain but extracted tribute from one king, and set up another as a client. This seems to have started a slow Romanisation of Britain with the local elites seeing the luxuries available in the Empire, and their sons going to Rome for a civilised upbringing (it isn’t quite clear if this export was voluntary). Britain already made some use of coinage which I find intriguing in a supposedly pre-literate society. There is scant archaeology from this period but a number of hordes of valuable items have been recovered.
The action then moves onto the Roman invasion in 43AD, over a 40 year period something like 250,000 Britons would lose their lives to the Romans, and it is likely 250,000 more were taken into slavery – this is from a population of around 2 million. The initial invasion force was around 40,000. The conquest was a slow process with some outright military victories and alliances or arrangements with the existing kingdoms as well as a lengthy and brutal campaign in Wales. The subjugation of Wales was to take until 51AD, veterans of this campaign retired to Camulodunum (Colchester) where they formed a colony. Relevant from this period is King Prasutagus of the Iceni tribe, whose wife was Boudica.
On his death Prasutagus in 59AD attempted to make his wife, Boudica, heir to his kingdom alongside Rome. Rome did not take kindly to this, Boudica was whipped and her two daughters raped. Subsequent events are recorded by Tacitus in The Annals (English version here, original latin here). There are also some references in Cassius Dio’s Roman History (English version here). These are relatively brief accounts and much of the understanding of events turns on a couple of sentences. Apparently Romans referred to us as Britunculi – “little Britons”!
In 60AD Boudica and her allies attacked the Camulodunum colony, killing effectively all of its inhabitants and burning it to the ground. The destruction can be seen in the archaeological record, and in fact burning has preserved more of the wattle and daub and other wooden structures than would normally be found. The final redoubt of the Roman colonists was the extravagant Temple of Claudius which was besieged for two days according to Tacitus.
On hearing news of the massacre the 9th Legion from set out towards Camulodunum via Cambridge. MacKay thinks they started from Longthorpe (outside Peterborough) whilst others suggested they started from their main garrison in Lincoln. This is where MacKay first takes to the road in earnest, travelling along the A14 to Cambridge, at the time this was the Via Devana (The Chester Road). MacKay is keen on his caligae (Roman hobnailed sandals) with which he walks some of the route. We lived in Cambridge for nearly 10 years and I know the A14 well, now we live in Chester. So this leg of the journey strikes a cord. The 9th legion were massacred somewhere outside Camulodunum, MacKay suggests the Colne Valley as a likely location for the ambush. This seems to be largely on the basis of where he supposed they were coming from and the local geography. There is no archaeological evidence for the battle.
In the meantime the Roman governor of Britain at the time, Gaius Suetonius Paulinus, is invading Anglesey where the last Welsh resistance is holding out. Tacitus notes of the women in the opposing forces ranks:
In the style of Furies, in robes of deathly black and with dishevelled hair, they brandished their torches; while a circle of Druids, lifting their hands to heaven and showering imprecations, struck the troops with such an awe at the extraordinary spectacle that, as though their limbs were paralysed, they exposed their bodies to wounds without an attempt at movement.
Despite this they are beaten easily by Paulinus’s legionnaires. MacKay travels to the vicinity of RAF Valley on Anglesey to start his retrace of Paulinus’s rapid trip south to face Boudica. We spent our summer holiday in Rhosneigr – a couple of miles away! The site is interesting because a number of artefacts were discovered in the lake there. One of them, a slave chain, was actually used by workers in the 1940s conducting a peat excavation operation and survived the experience remarkably well!
It is thought that Paulinus prepared his invasion boats (likely flat bottomed barges), in Chester and on his trip back to London – on news of Boudica’s rebellion – at least part of his force probably sailed back to Chester. Paulinus then takes his force south to London likely heading down towards Wroxeter (near Shrewsbury) along the now vanished start of the Watling Street Roman road before following it onwards to London along the still existing line of Watling Street. MacKay follows this route by car stopping on the outskirts of London to travel by rail and foot to the area of Monument, the centre of Roman London.
In 60AD London was a thriving trading centre but does not appear to have been an important town to the Romans from an administrative point of view, furthermore it did not have significant defences at the time so on his arrival Paulinus decided to abandon London to Boudica’s forces who were heading down from Colchester. He departed with those able and willing to follow, some may have taken refuge from Boudica on boats in the Thames. In any case London was comprehensively burnt by Boudica’s forces. Paulinus then headed up toward Veralumium (near modern day St Albans) which Boudica also destroyed.
That was the limit of Boudica’s rebellion, MacKay spends some time visiting potential locations for the final Great Battle of which Tacitus just says “…a position approached by a narrow defile and secured in the rear by a wood…“. This location has been the subject of much discussion with locations up into Warwickshire finding favour. MacKay appears to have decided on Windridge Farm close to Veralumium on the basis of the geography of the area, the proximity to a know location for Boudica and the discovery of clusters of Roman slingshot . Wherever it was Tacitus claims 80,000 of Boudica’s forces were killed in a single engagement, for comparison the first day of the Battle of the Somme saw 20,0000 British troops died. This ended Boudica’s rebellion and Tacitus says she died by her own hand afterwards.
The Roman’s lost a similar number of soldiers and civilians during the rebellion. What surprised me is despite these huge battles in the Colne Valley, on Anglesey and close to St Albans there is minimal archaeological evidence from these sites. Part of the problem is no doubt the uncertainty of their location, but also 80,000 dead on the ground surface would likely disappear over a period of a few years. Armour and weapons were valuable and would have been cleared from the battle field. MacKay references reports from other Roman battles, the Indian Rebellion and a battle between the British and Zulus, as to how such locations appeared after a few months or years.
The Romans were brutal occupiers, as evidenced by their own historians, and the carved columns they raised in honour of victorious generals. Boudica’s forces were brutal too. It would have taken the Romans a number of years to recover from the rebellion, furthermore the local population struggled through famine in the aftermath of the rebellion (Tacitus puts the blame for this squarely on the British).
I enjoyed this book, I thought the combination of travelogue and history worked really well and by chance I was familiar with a number of the locations MacKay visits.
About

I've worked as a scientist for the last 30 years, at various universities, a large home and personal care company, a startup in Liverpool called The Sensible Code Company (formerly ScraperWiki Ltd), GBG and now as a consultant in data science.
I write about:
* the books I have read, typically science and history (or both), partly as a reminder to myself and partly as a review;
* science, things I have done or things I find interesting;
* technology, programming and gadgets;
politics, and current affairs;
* ...and other stuff as it takes my fancy - holidays, photographs and things I want to remember.